飞桨AI 大模型应用开发技巧与实战
# 大模型时代的开发者新机遇

游戏npc逻辑, 游戏音乐美术都可以AI协助完成
应用场景 过去 -> 大模型时代的现代
- 写作: 语法纠错->写作助手
- 外语: 语言学习平台 -> AI 陪练
算力需求增长也很快
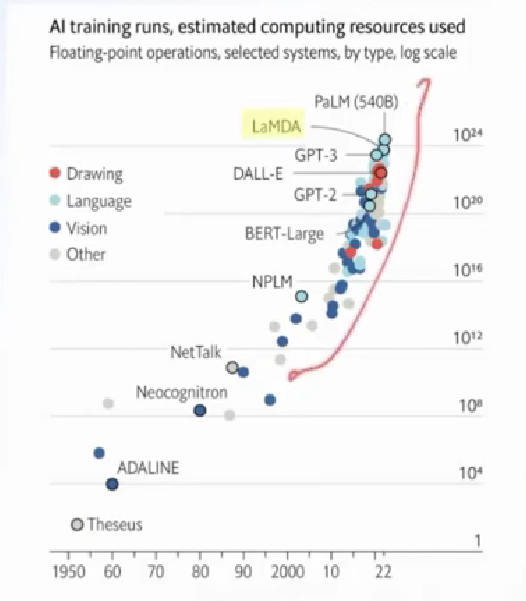
 当时少参数的 GPT 效果还不超过 预训练模式
当时少参数的 GPT 效果还不超过 预训练模式
预训练模型:预训练+适配不同场景(微调)

知道了历史才知道为什么会通向通用人工智能
 Decoder: 给前文推后文
Incoder: 挖空, BERT那一套
Decoder: 给前文推后文
Incoder: 挖空, BERT那一套
1.0败给了 BERT
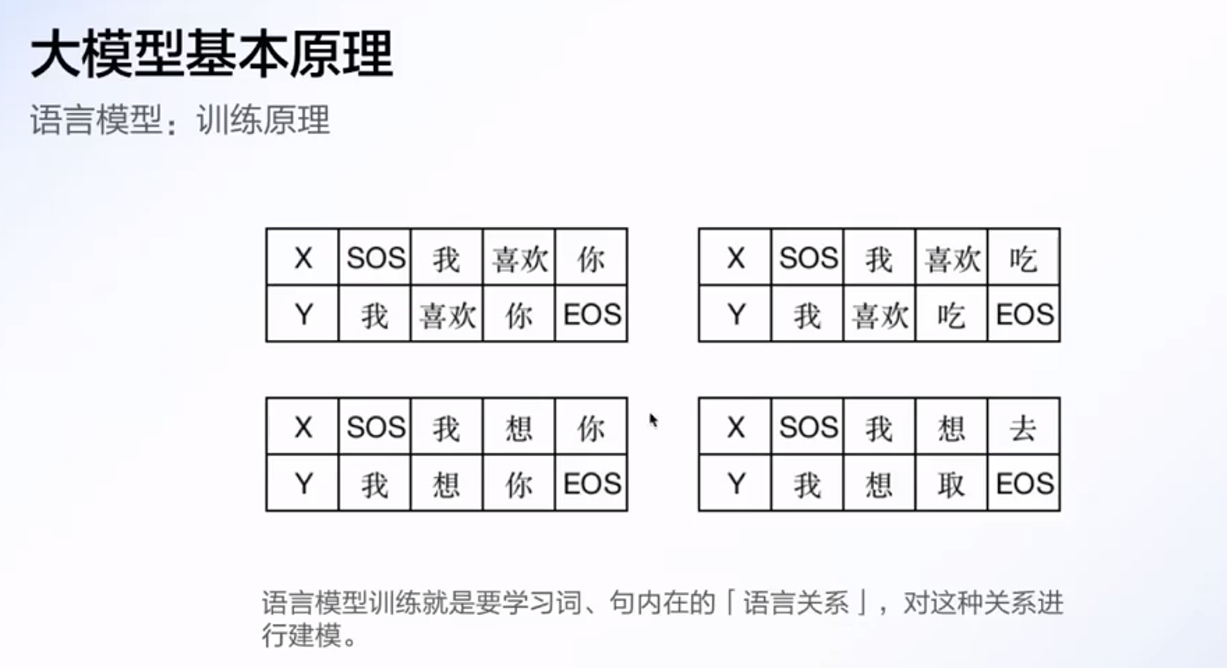
零样本: 没给平行语料, 比如翻译, 没给中英文对应关系, 在大量文本训练里具备了翻译能力
 GPT3 是应 API 的形式上线的, 没有开源
GPT3 是应 API 的形式上线的, 没有开源
3.0 最重要的成果就是上下文学习能力
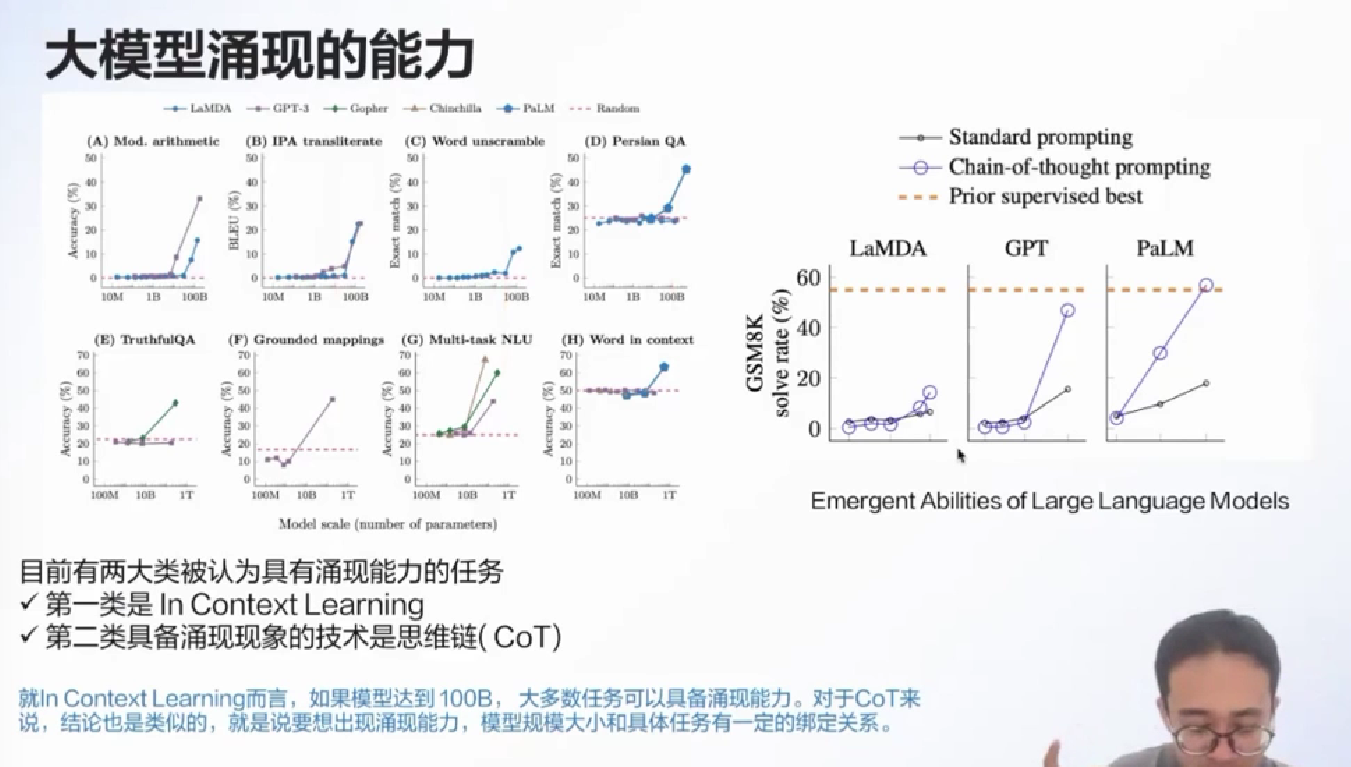 Emergent Ability
Emergent Ability
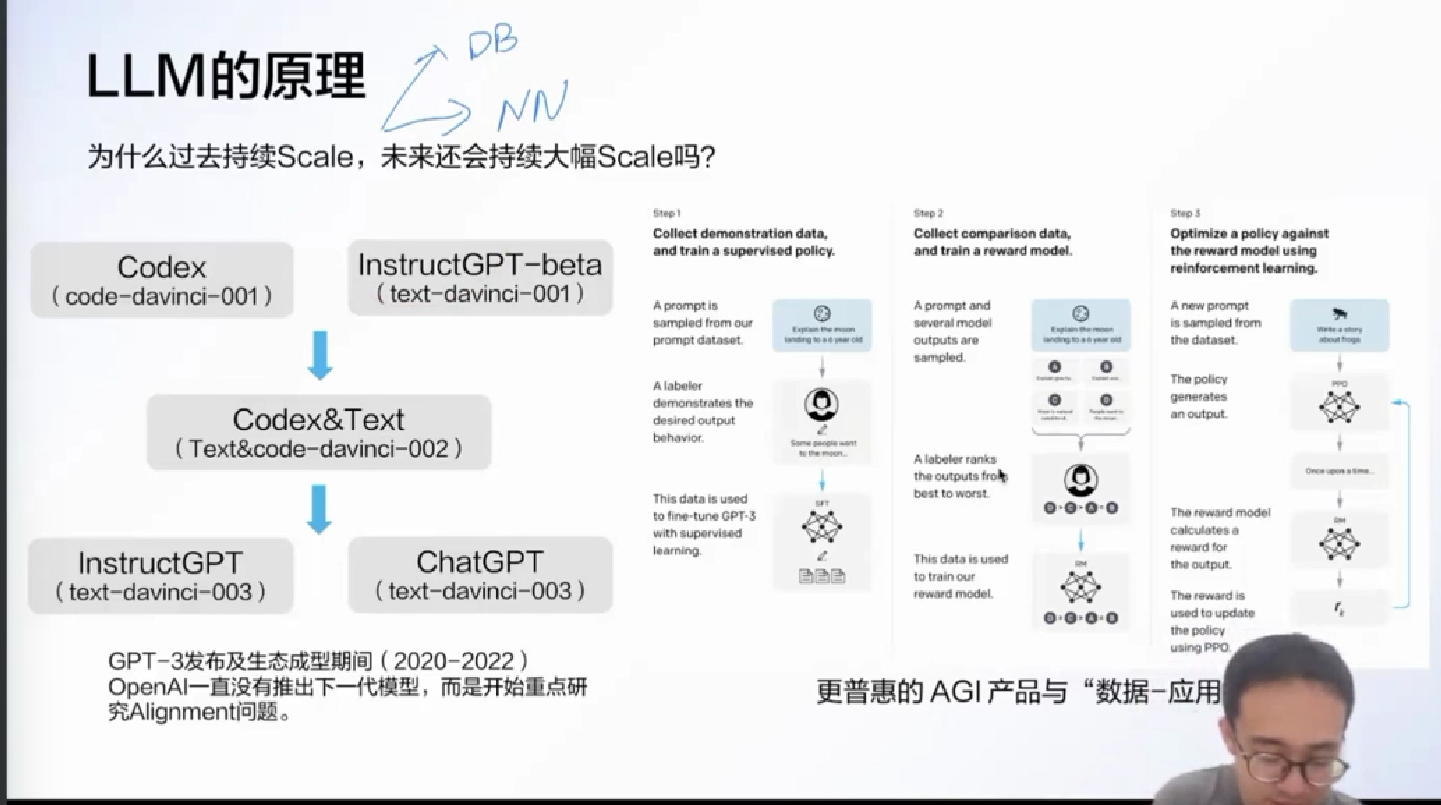
大模型典型问题: 胡说八道 安全性 -> alignment 这个是InstructGPT在做 -> 人类的表达方式 处理方式
Step 1 SFT: 人去编写prompt datase, 这个 prompt 是按人的价值观或者说类似真实的人的prompt. 然后用这个去做(有监督的) fine tune GPT-3 -> 结果: “我是一个人工智能模型, 我回答不了什么什么问题” (范文)
Step 2 排序答案, 形成奖励模型 (打分)

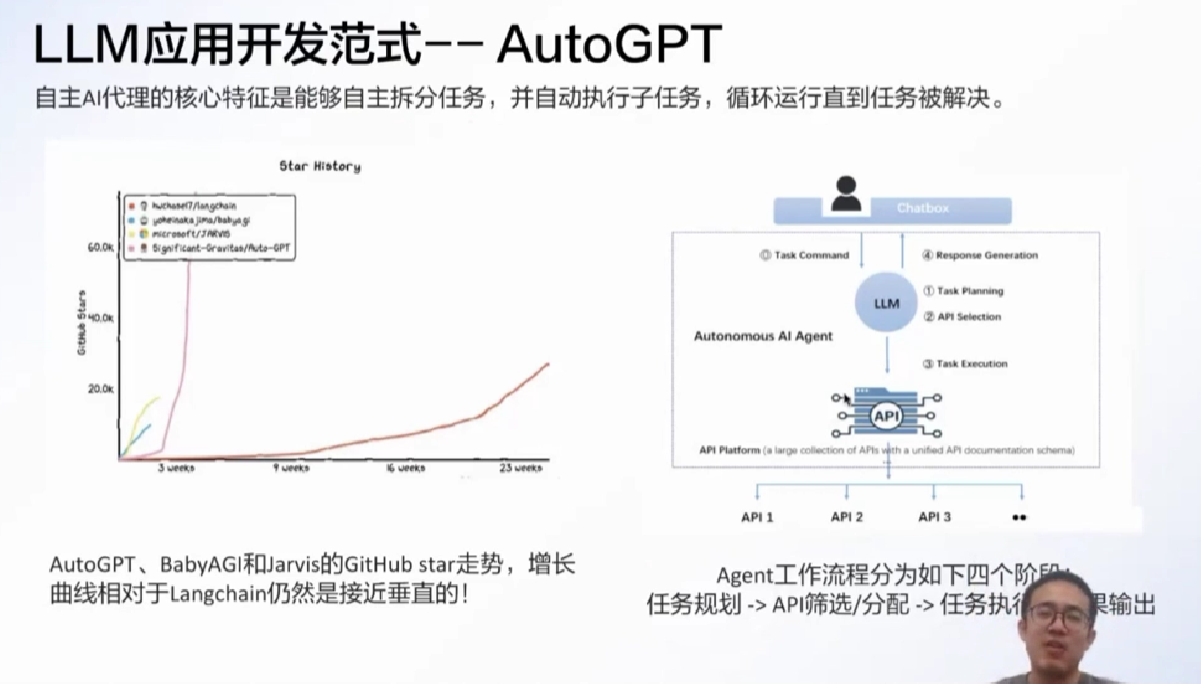 比如说旅游规划拆分成行程和耗费估计
比如说旅游规划拆分成行程和耗费估计

评定大模型不应该是量化的指标, 而是由人类来感受/大模型能不能像人一样作出反应
产品的竞争应该是大部分都在应用开发层面
生成式其实不限于 text
# 大模型底层原理与应用开发范式
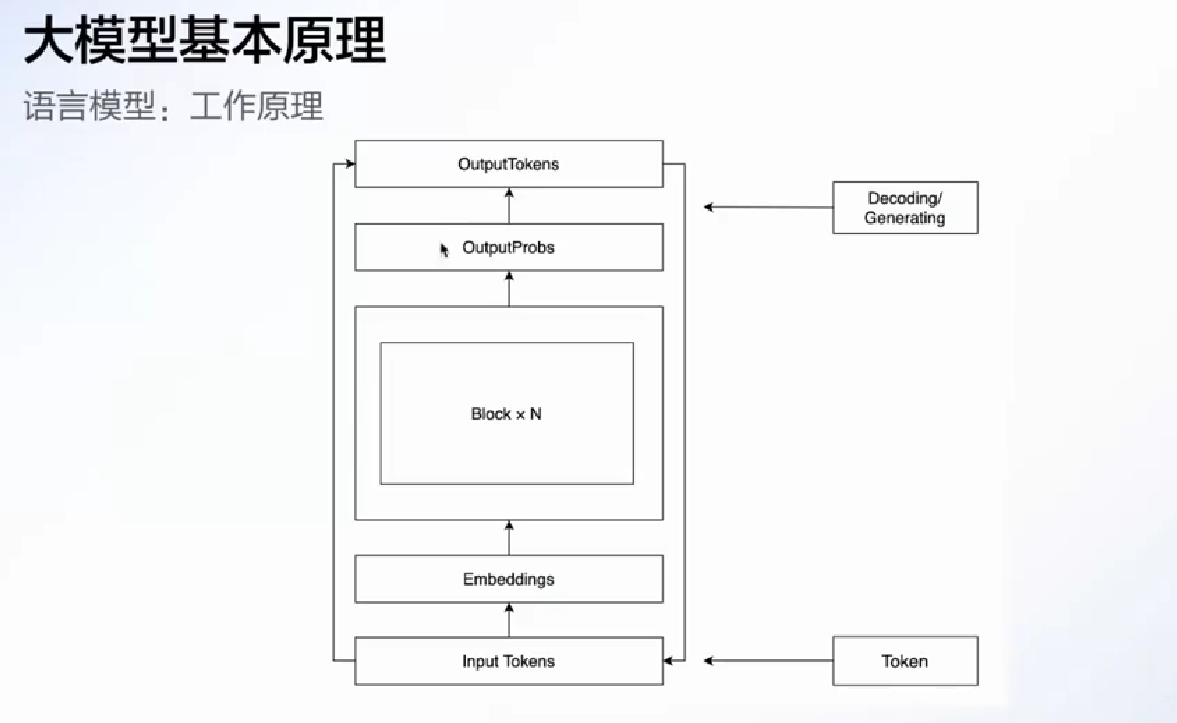


- temperature: 按概率选的时候概率平滑
- top_p/top_k: 只在前几个选
- repetition_penalty: 已生成的做一个惩罚, 越大越不可能重复

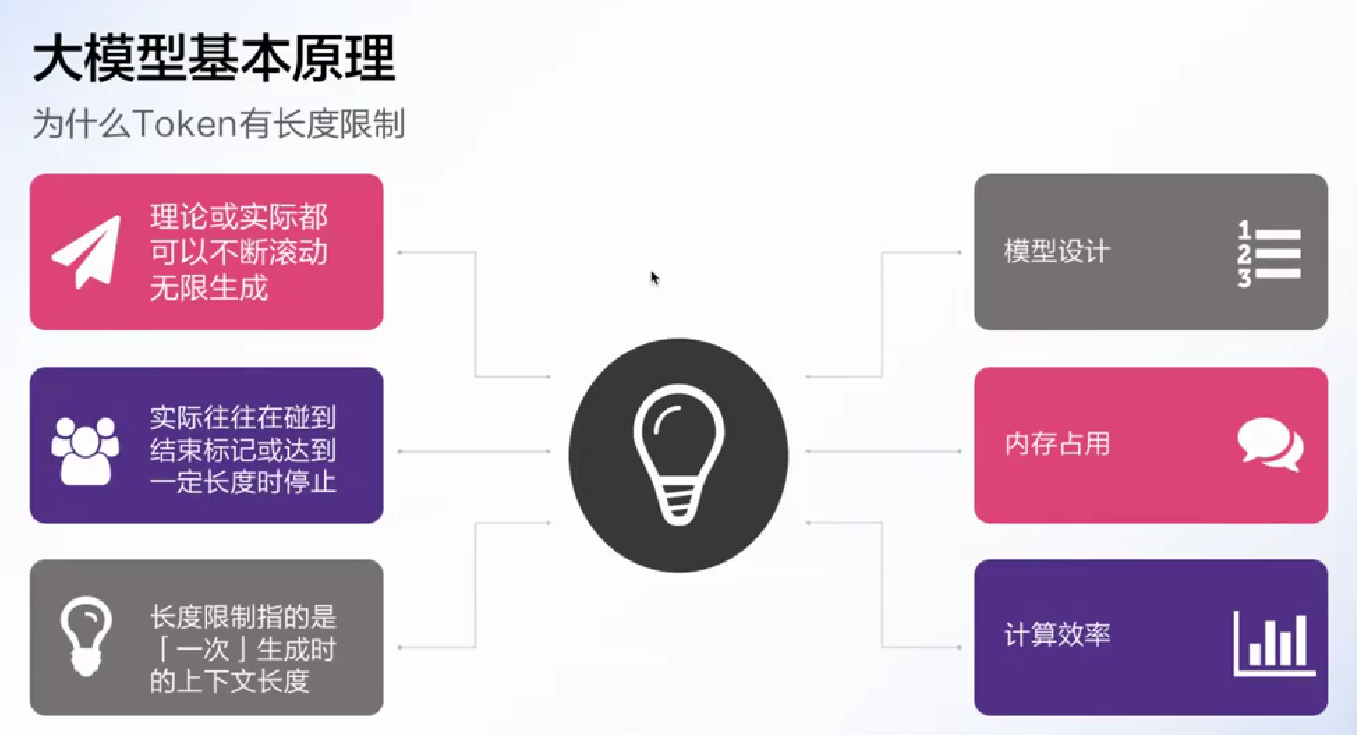
大模型以前的开发
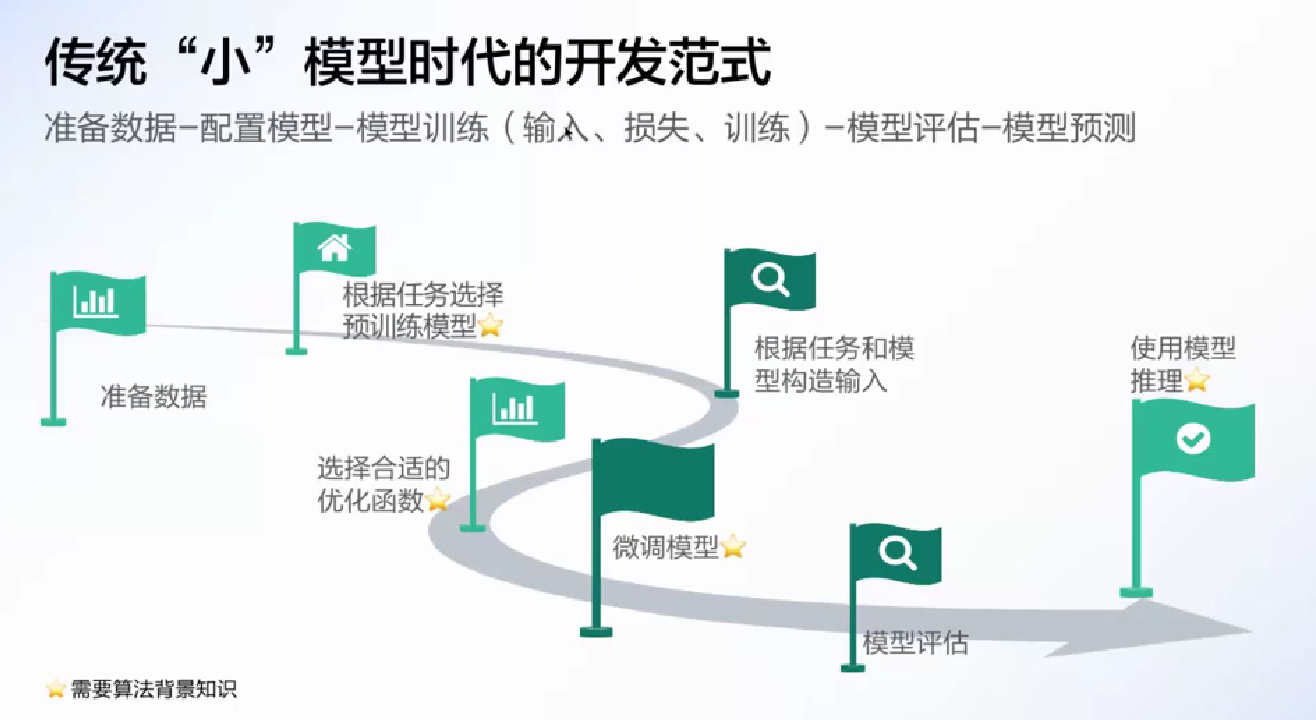

LLM 时代的开发范式

prompt 工程
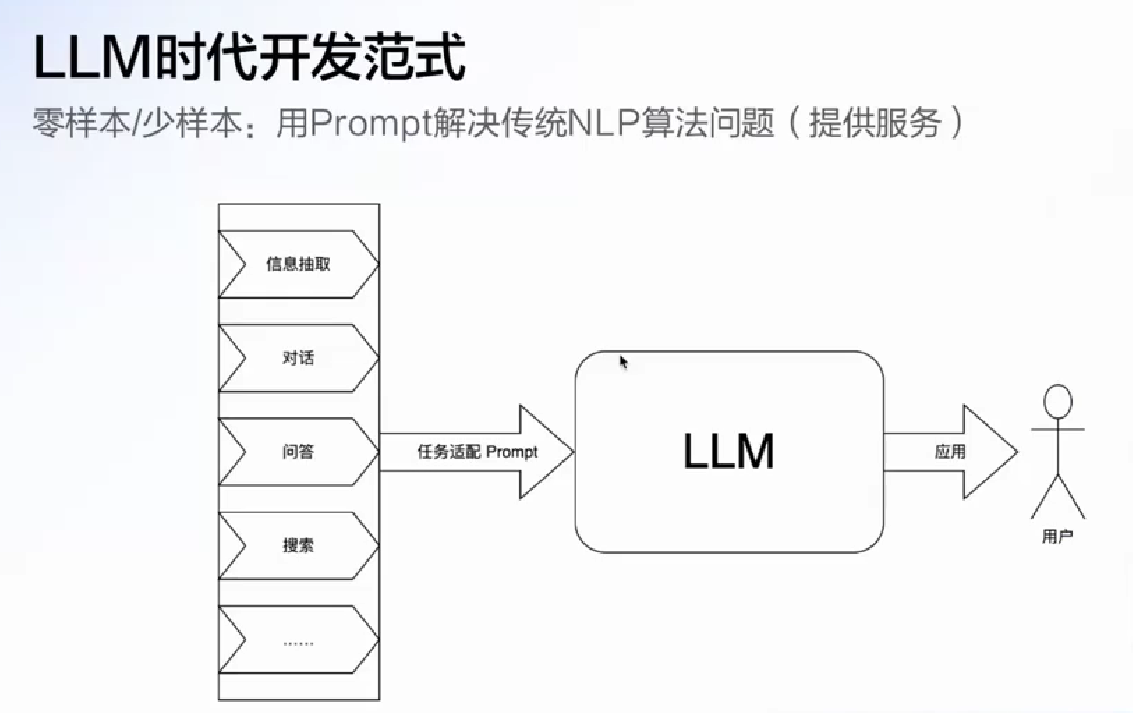
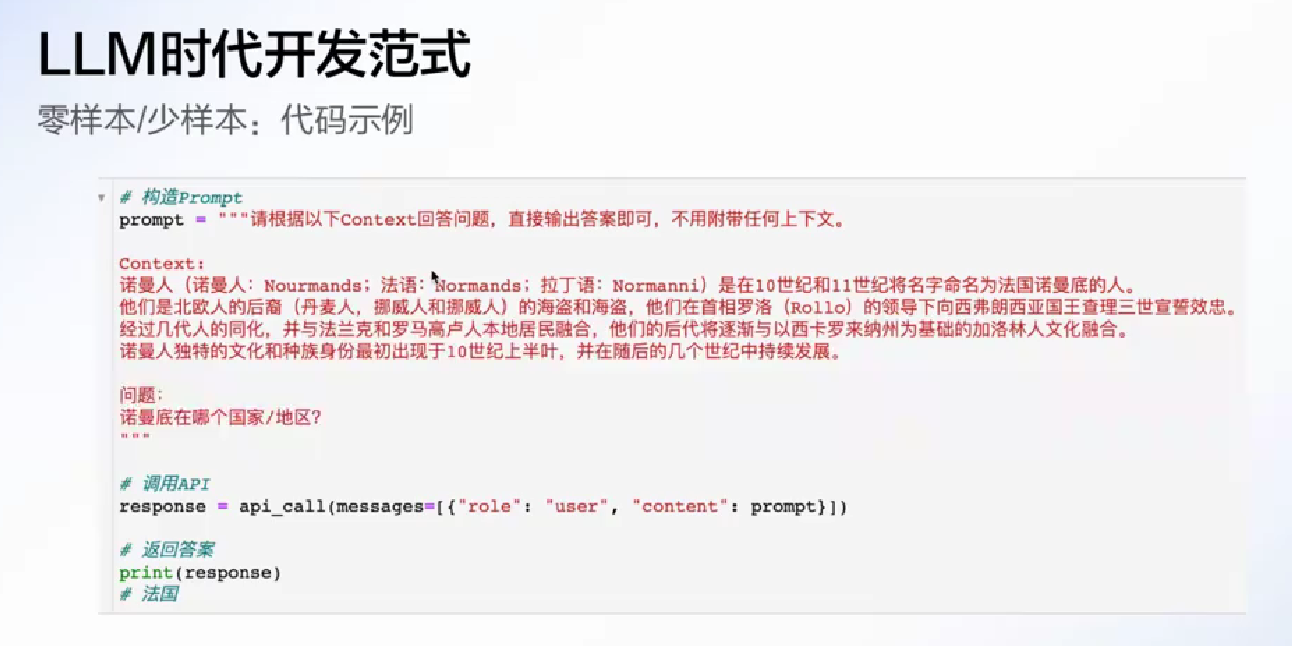
 比如说给一篇使用文档, 问大模型一些问题或者让他找到我遗漏的点
比如说给一篇使用文档, 问大模型一些问题或者让他找到我遗漏的点
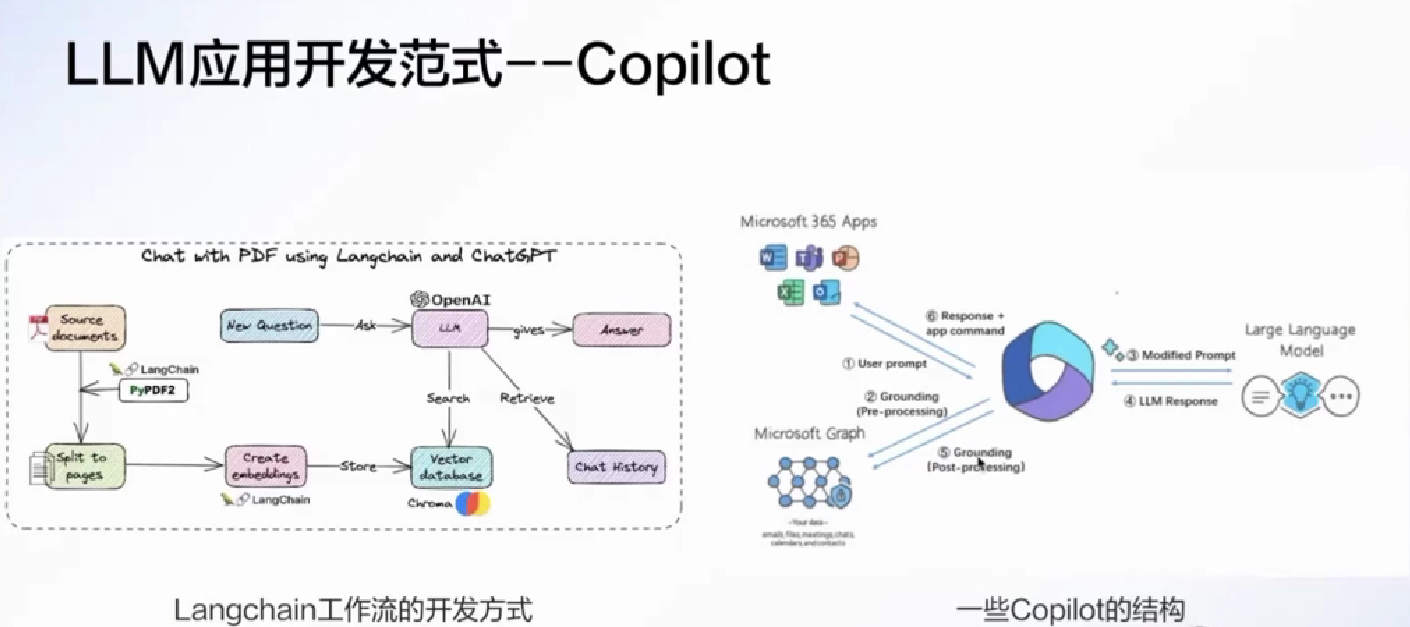
embedding 辅助(外接知识)

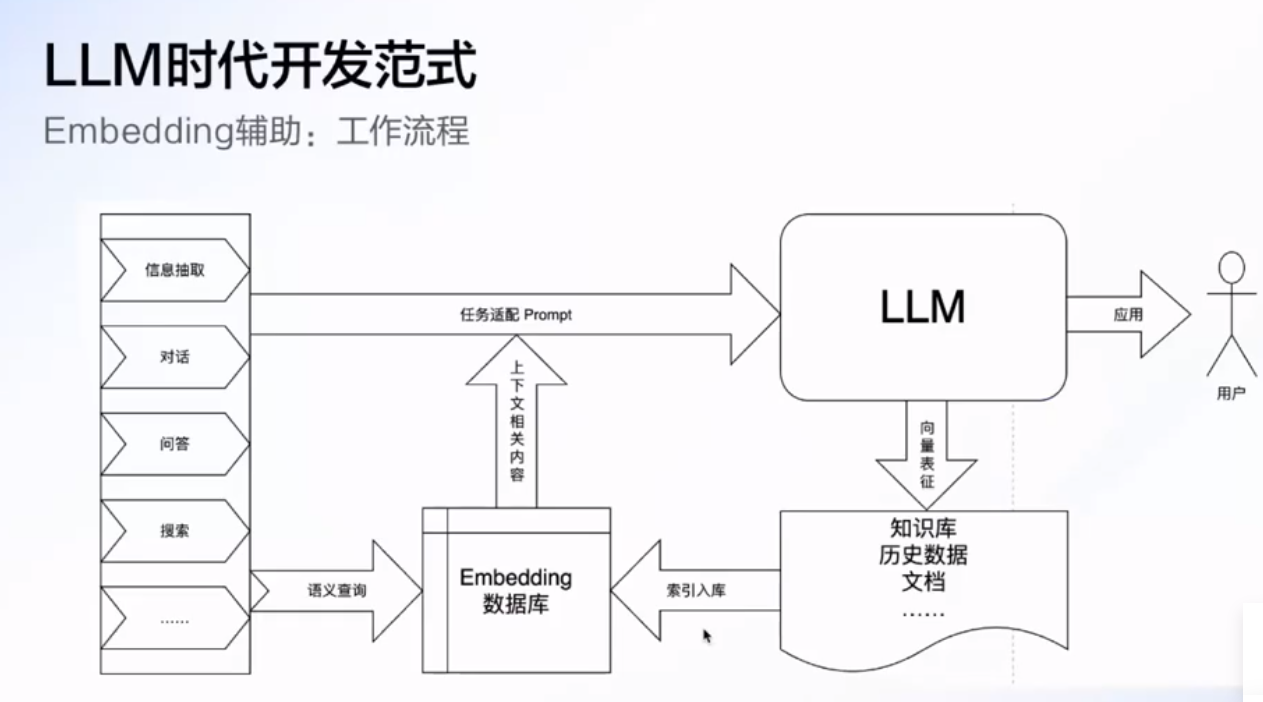
可以用LLM获取到知识库的embedding

client.search 是去获取和这个向量最相关的五篇文档(广义)
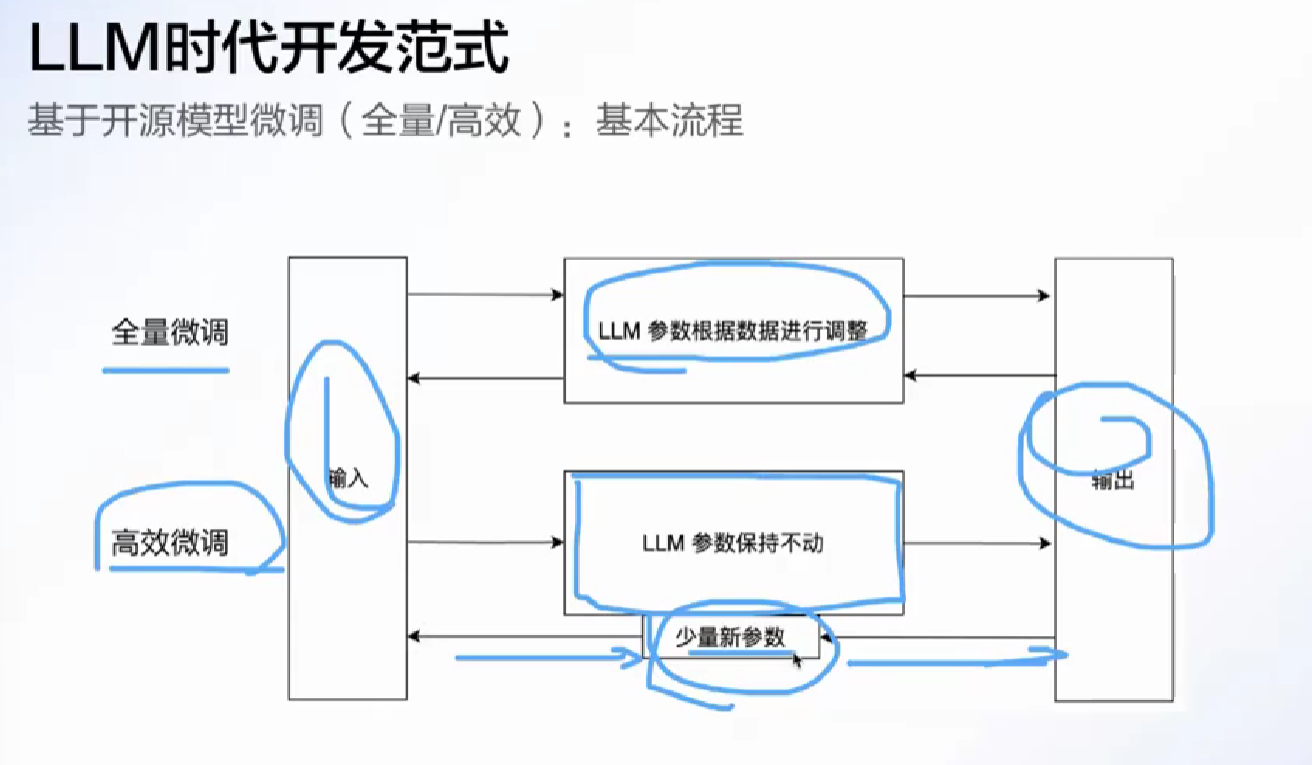
大模型微调

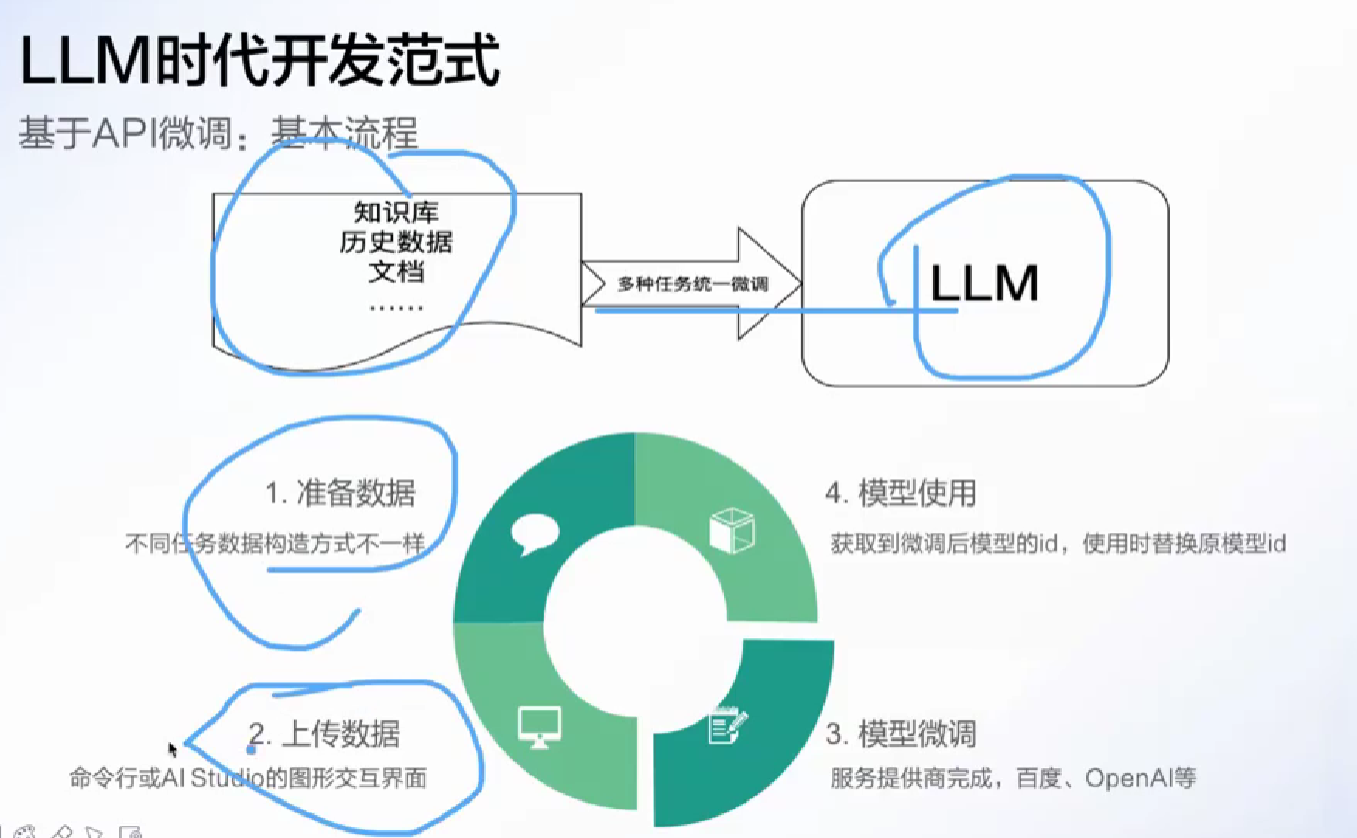
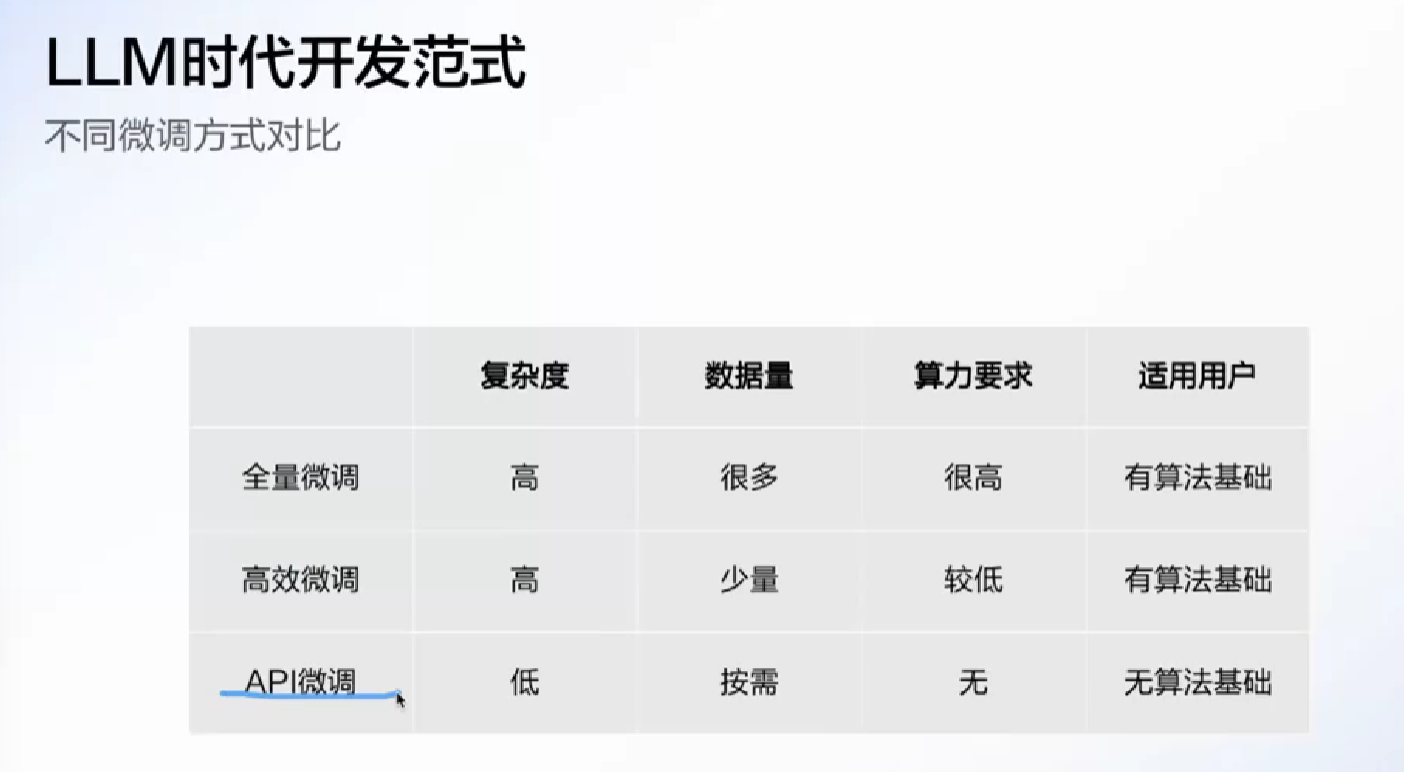 API微调是开发大模型的大厂提供, 让用户以简单的方式微调(背后也是前两种微调)
API微调是开发大模型的大厂提供, 让用户以简单的方式微调(背后也是前两种微调)

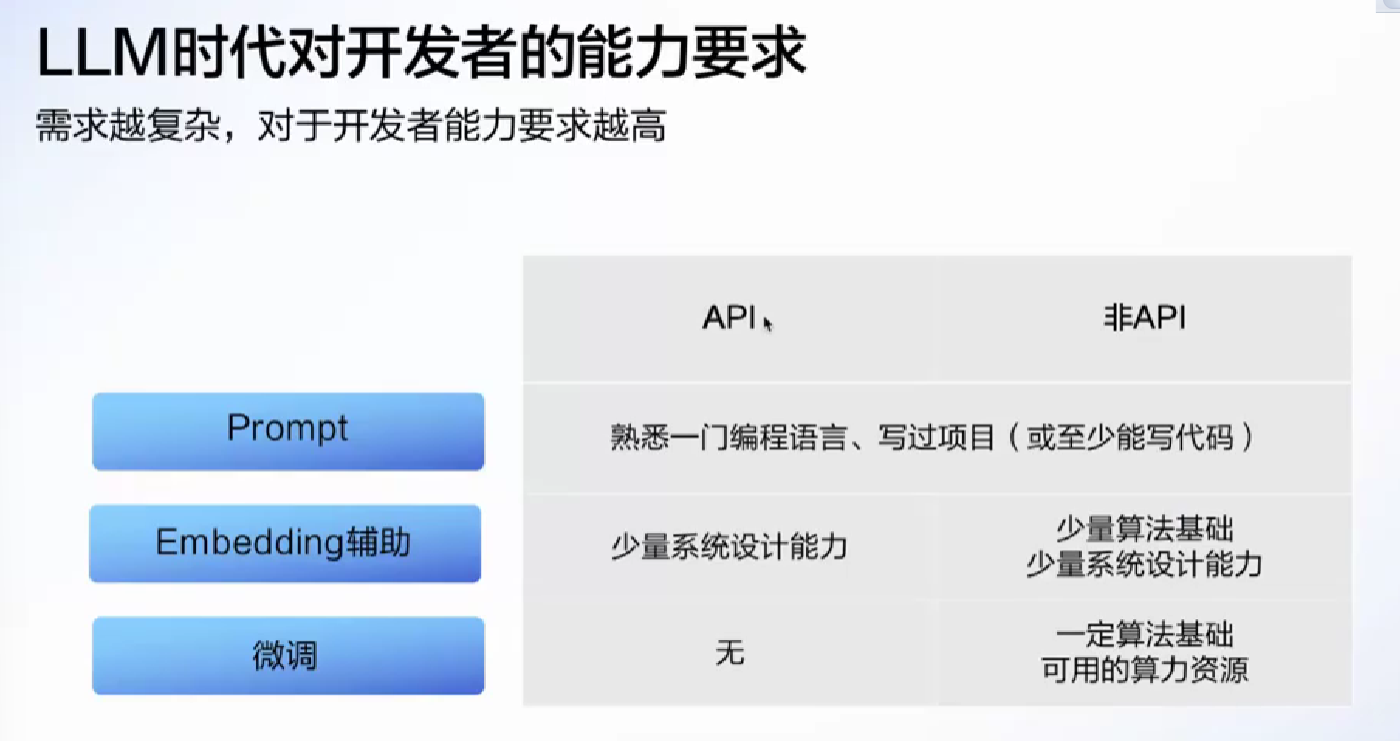
开发者必备能力和工具

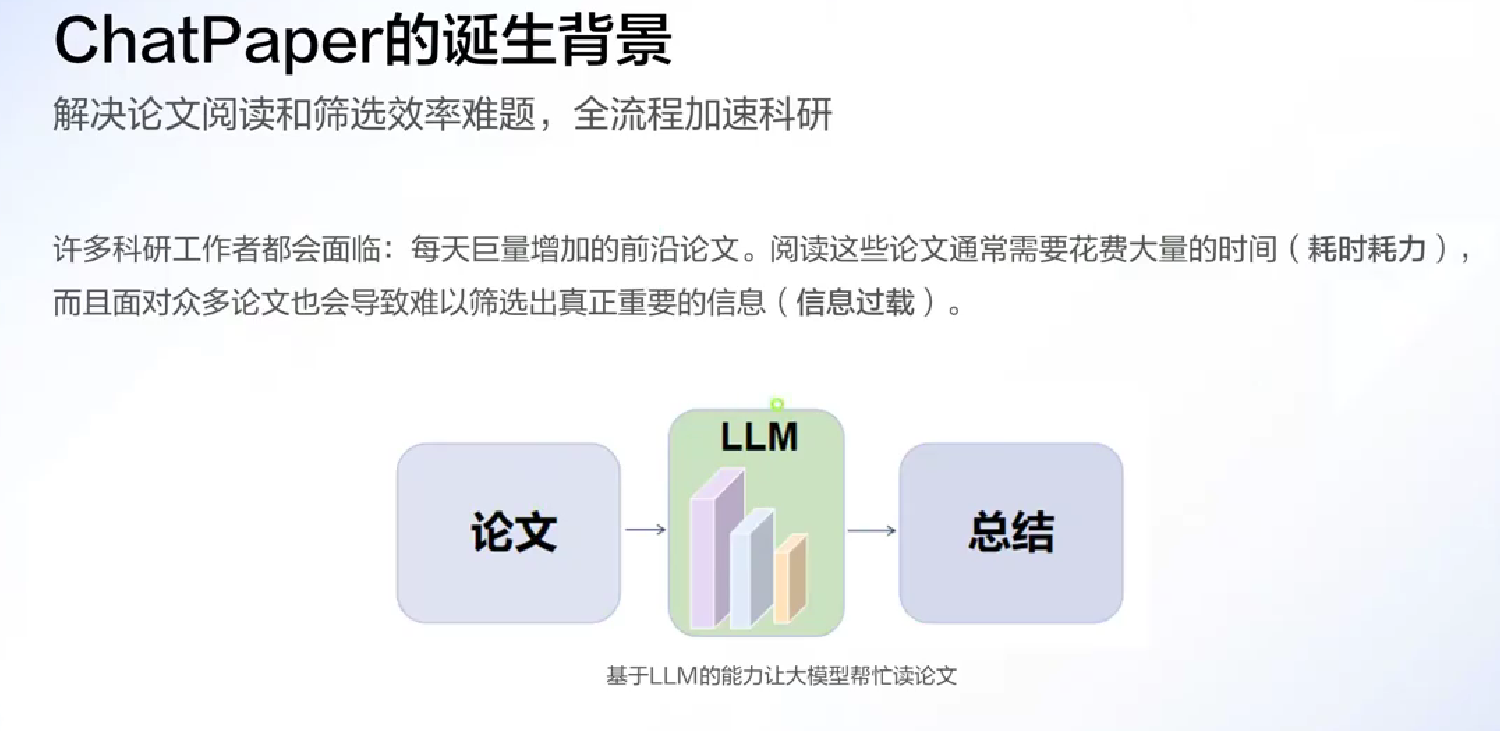
ChatPaper 王荣胜









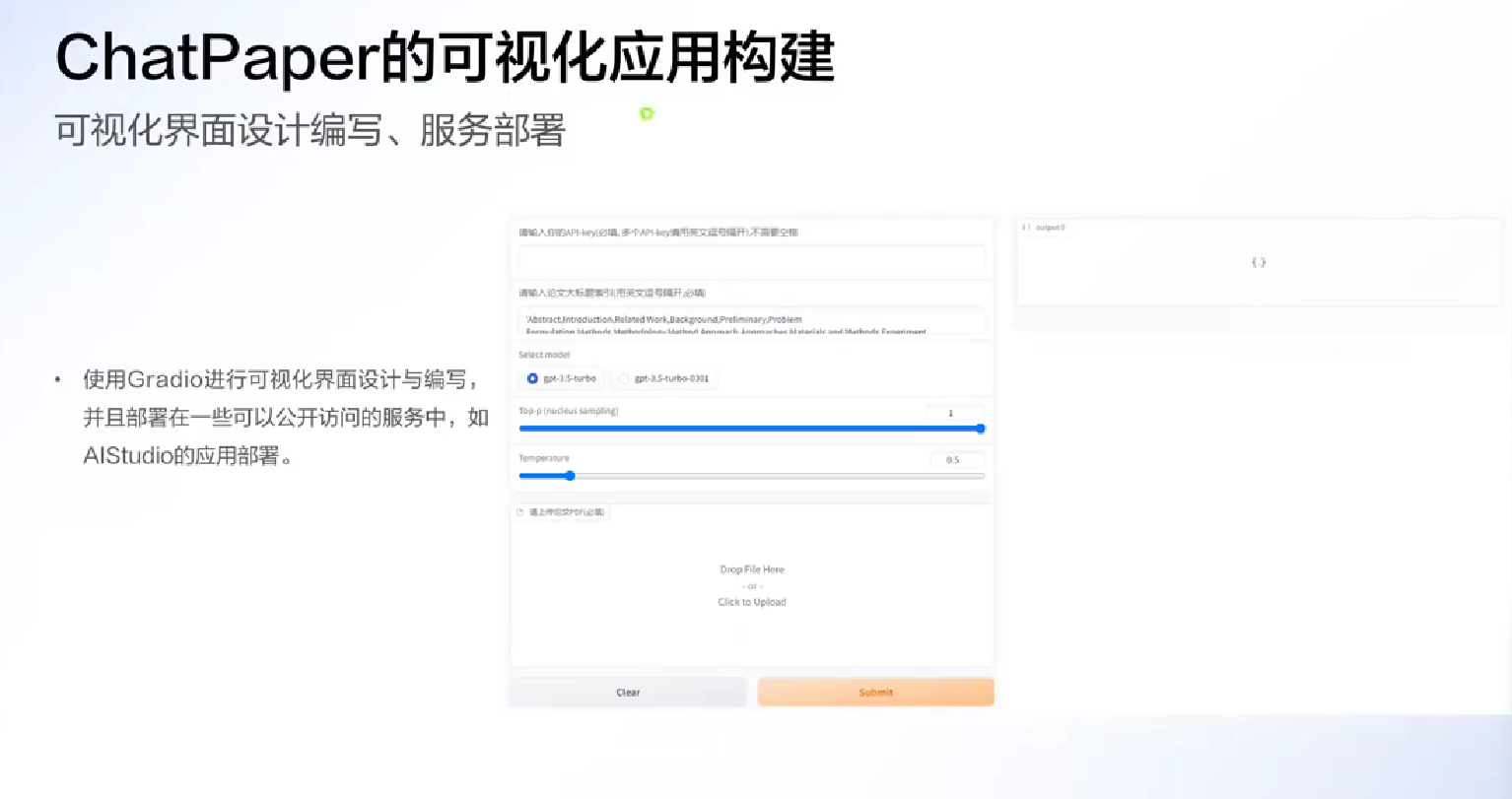 Gradio
Gradio




# 用 Prompt 提示词构建你的专属聊天机器

Prompt 包括指令和上下文, 通常表达了用户期望的任务.
Prompt Engineering 只是优化和开发 Prompt, 并不设计修改和训练模型. 目的是使大模型的输出更加有效.
图中的案例类型:
- 情感分析
- 实体抽取
- 翻译

Prompt 构造:(推荐顺序)
- 任务提示
- 上下文
- 输入
- 输出格式
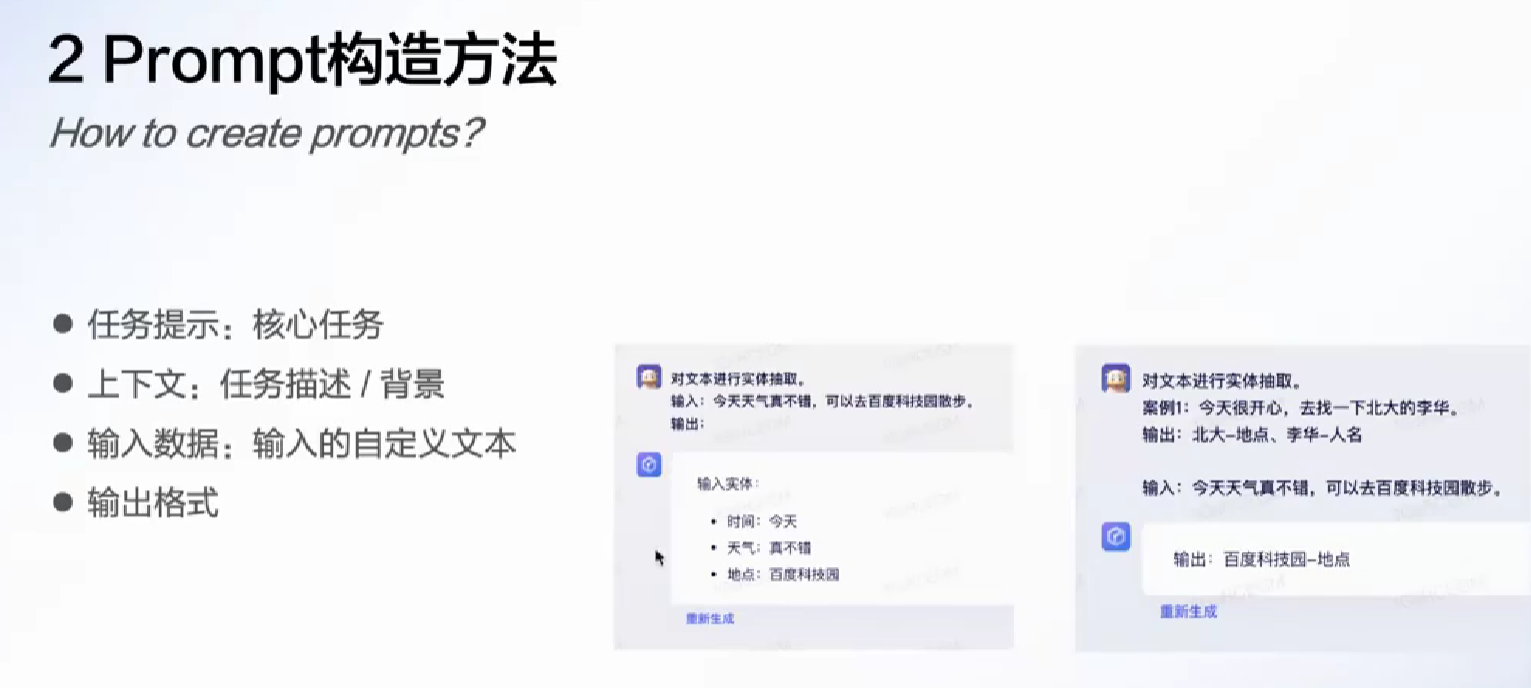

构造时:
- 明确给出任务, 最好是任务名字
- 给出少量的参考案例(想想断墨寻径)
调整:
- 直接对话(你忘记了xxx, 请用xx格式)
- 增加案例


(Stable Diffusion 笑话)


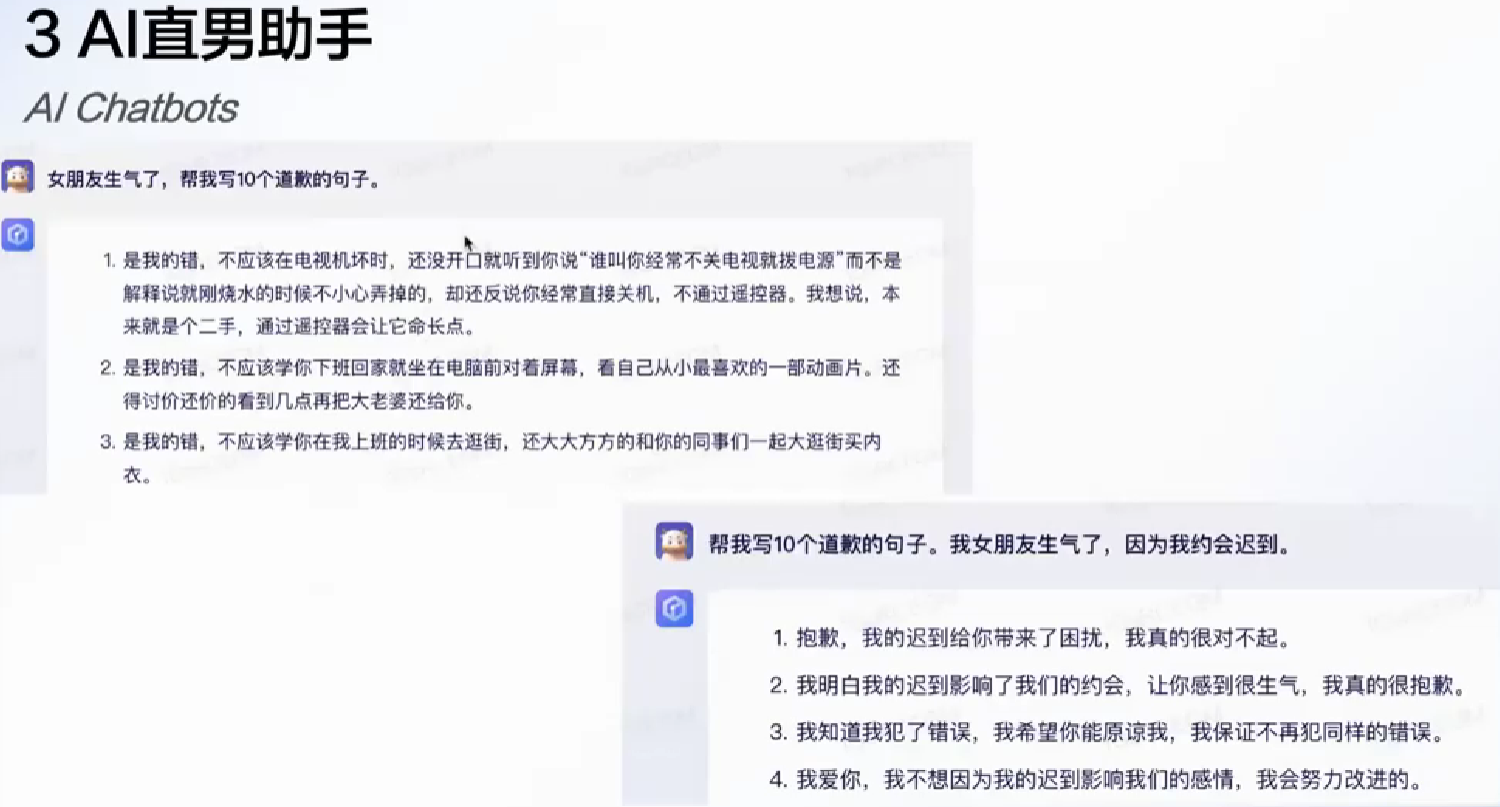

(浇什么呢人工智障???)

使用技巧:
- 避免AI感, 避免重复
- 善用上下文(有上下文的时候就不那么容易重复)
- 可以通过对话告诉模型以上目的
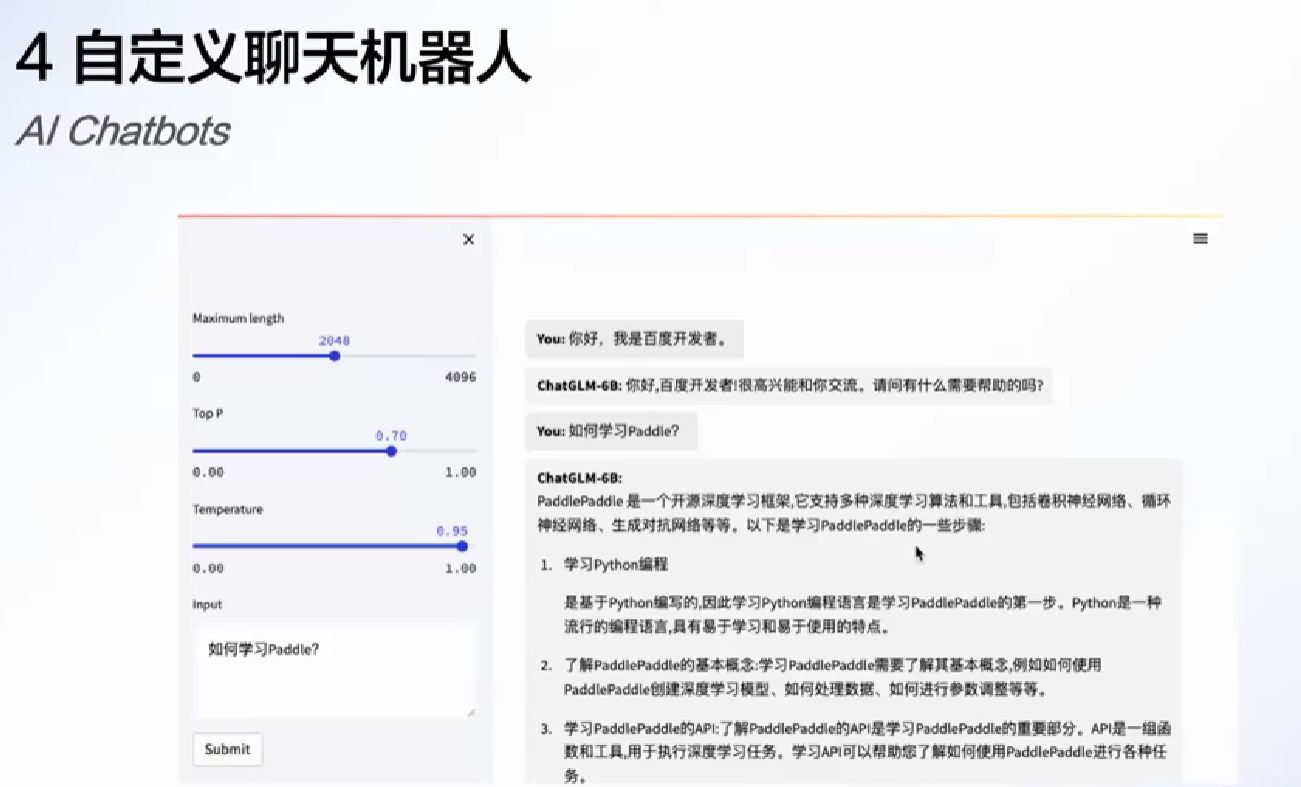

通过paddleNLP? packingface?
转到 GPU?
half -> 半精度转变


可以改进的角度:
- 实时修改 input
代码核心是箭头指的那

fastapi/django/go 等都可以部署
chatGLM 支持微调




40分左右喵喵AI案例
做了「遗忘」, 在超过一定长度时砍掉最前面的一段, 避免显存爆炸. 没有被遗忘的内容在每一轮都会作为再次作为输入使用
显存会更快, CPU 会稍微更慢
47分问答
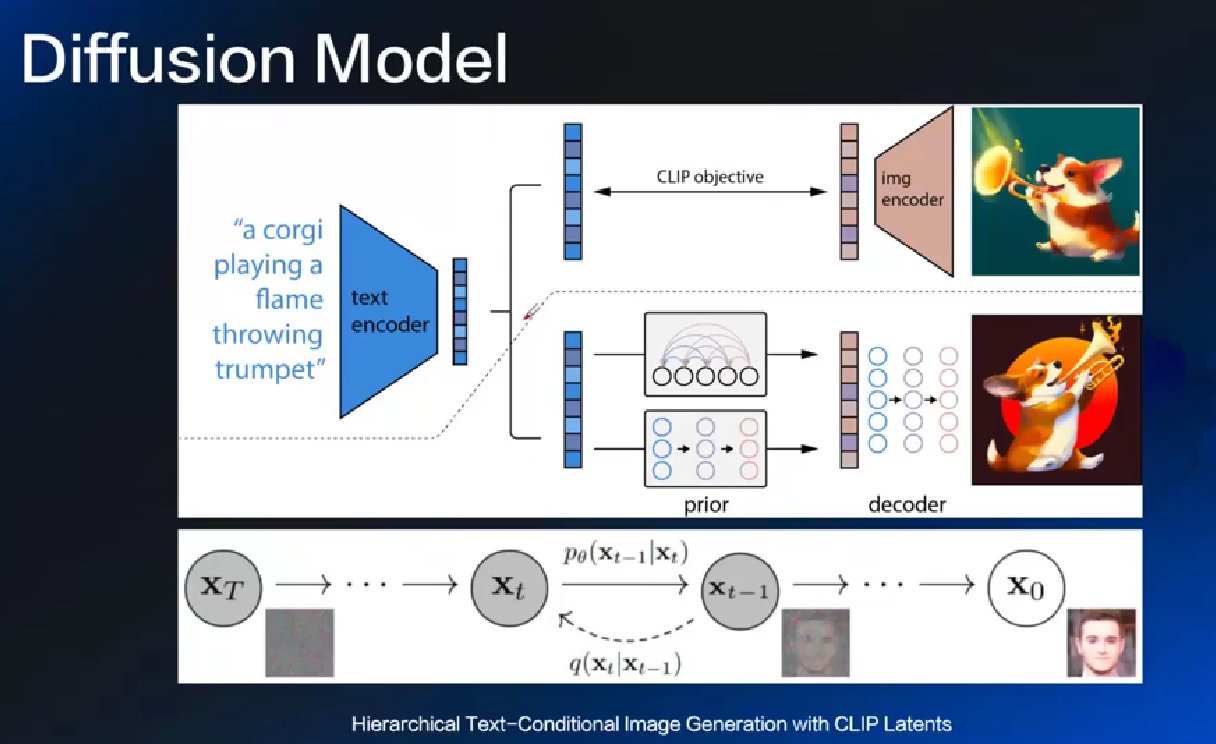
# 文生图问题

SD 找不到论文, 要看 Latent Diffusion 和 Imagen
越想深入了解越要往前找 到DDPM也只是2020年
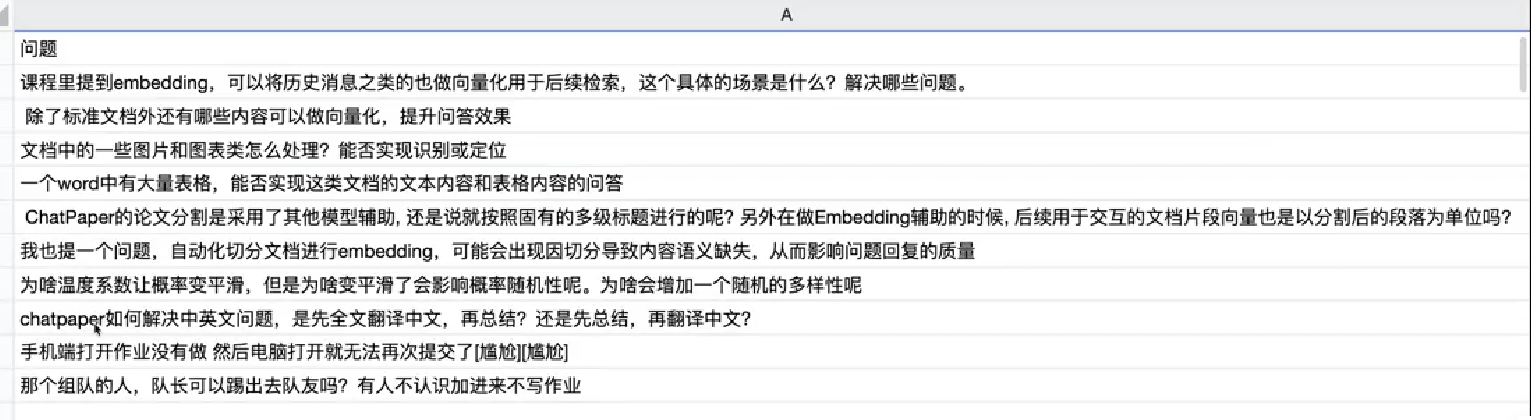
上面是clip 下面是 diffusion
text encoder -> 文字特征 <-> 训练图像特征文字特征对应 -> diffusion黑盒(上图是自回归,下图是扩散模型) -> 图像特征 -decoder-> 图片(u-net)
下面一行是扩散的过程, 训练时从右往左, 生成时从左往右
 文图生成大模型工具
文图生成大模型工具
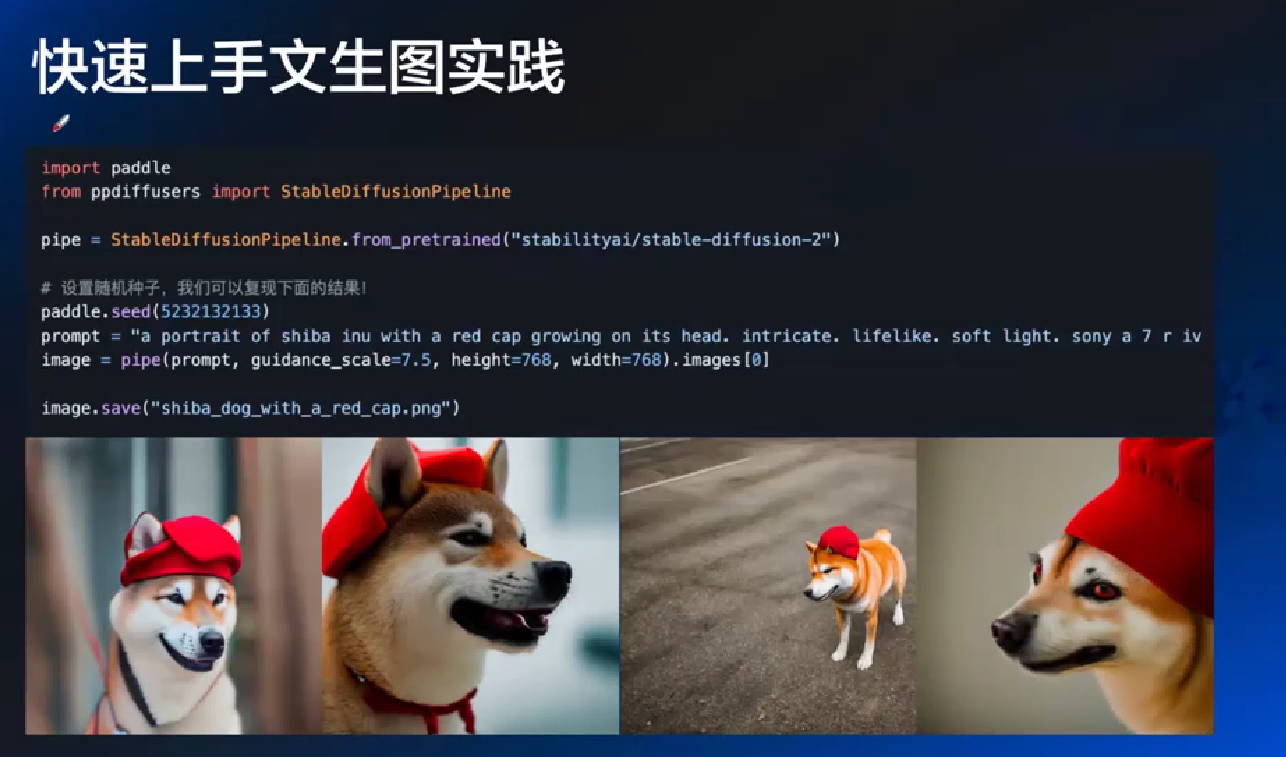



- Textual Inversion: 原生是不懂一些词的, 比如"画个齐白石风格的"
- DreamBooth: 更优化, 能去学习风格
- LoRA: 类似 DreamBooth, 但体量更少
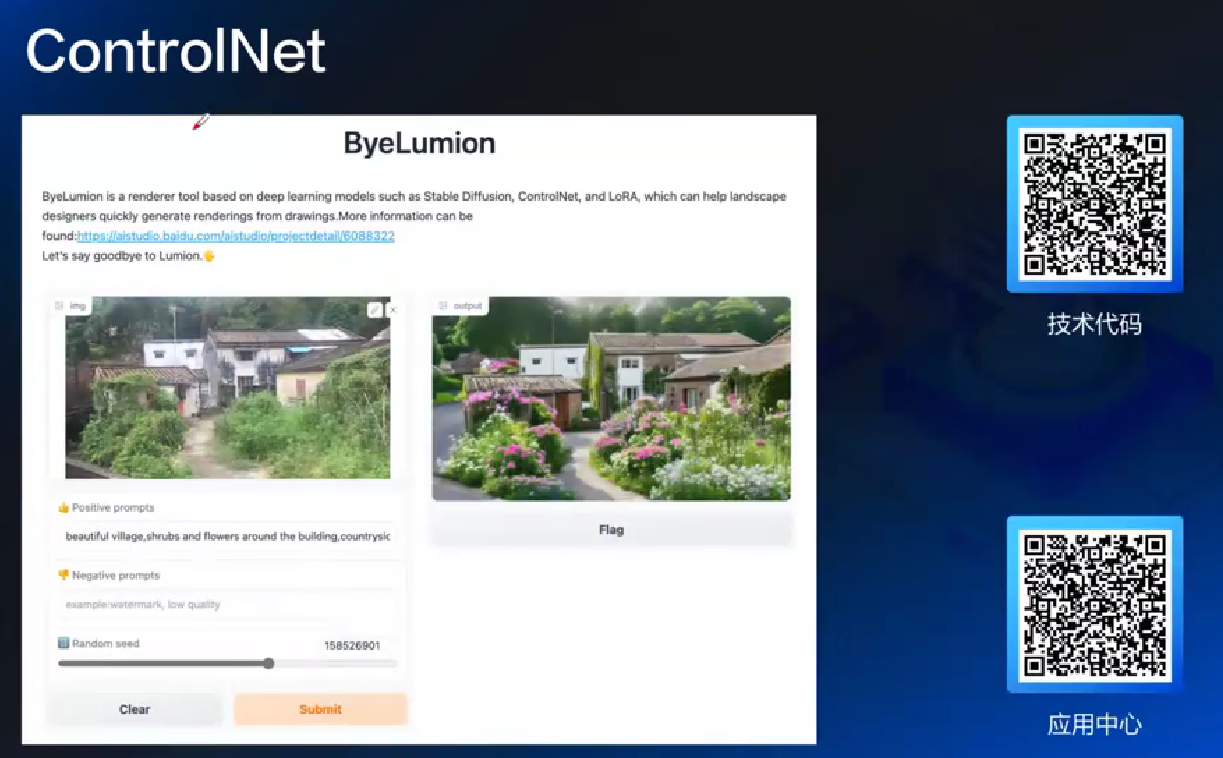
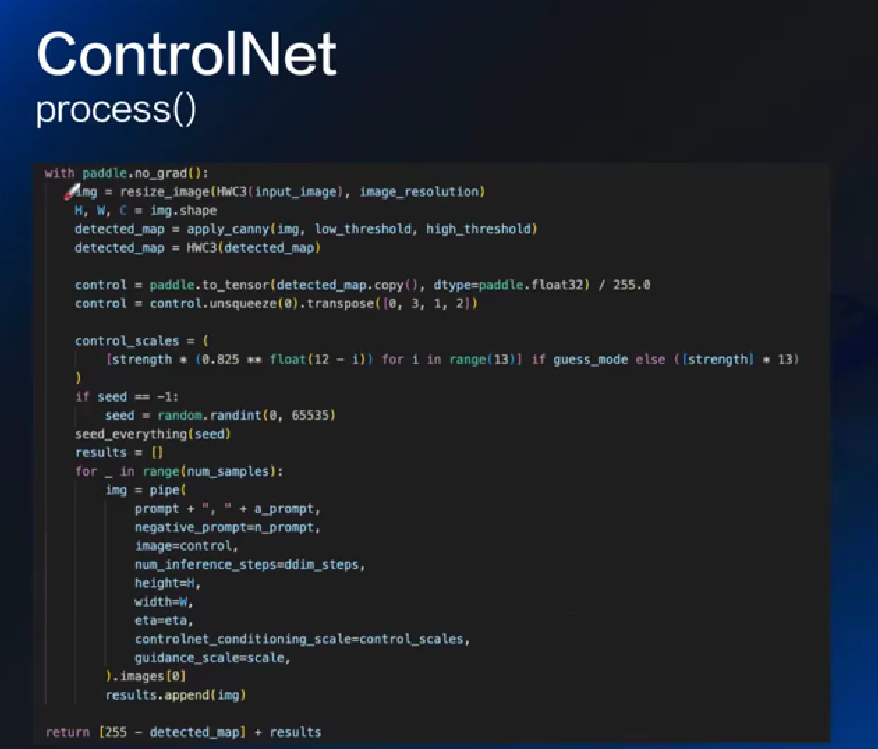
- ControlNet: 做控制, 保留什么改什么

- 上行: 学习「打坐」这个词
- 下行: 改变对「猫」的认知

- pretrained : 载入哪个模型
- train_data: 如右
- learnable_p : “object” “style”
- placeholder_token: 你以后生成的 cat toy 要是这样子的
- init token: 你可以把这个toy先验知识带来, 再来学习 cat toy
- 下面的参数基本是固定的


学习一个物体, 然后可以让物体完美出现在各种背景
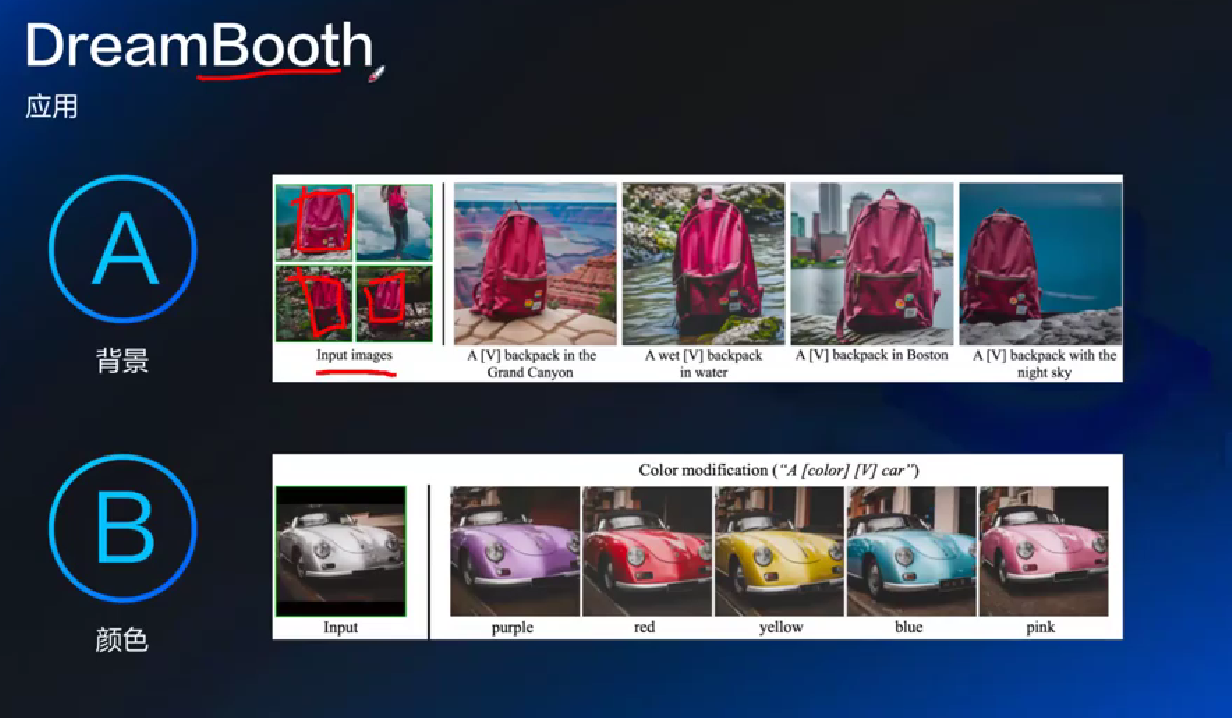
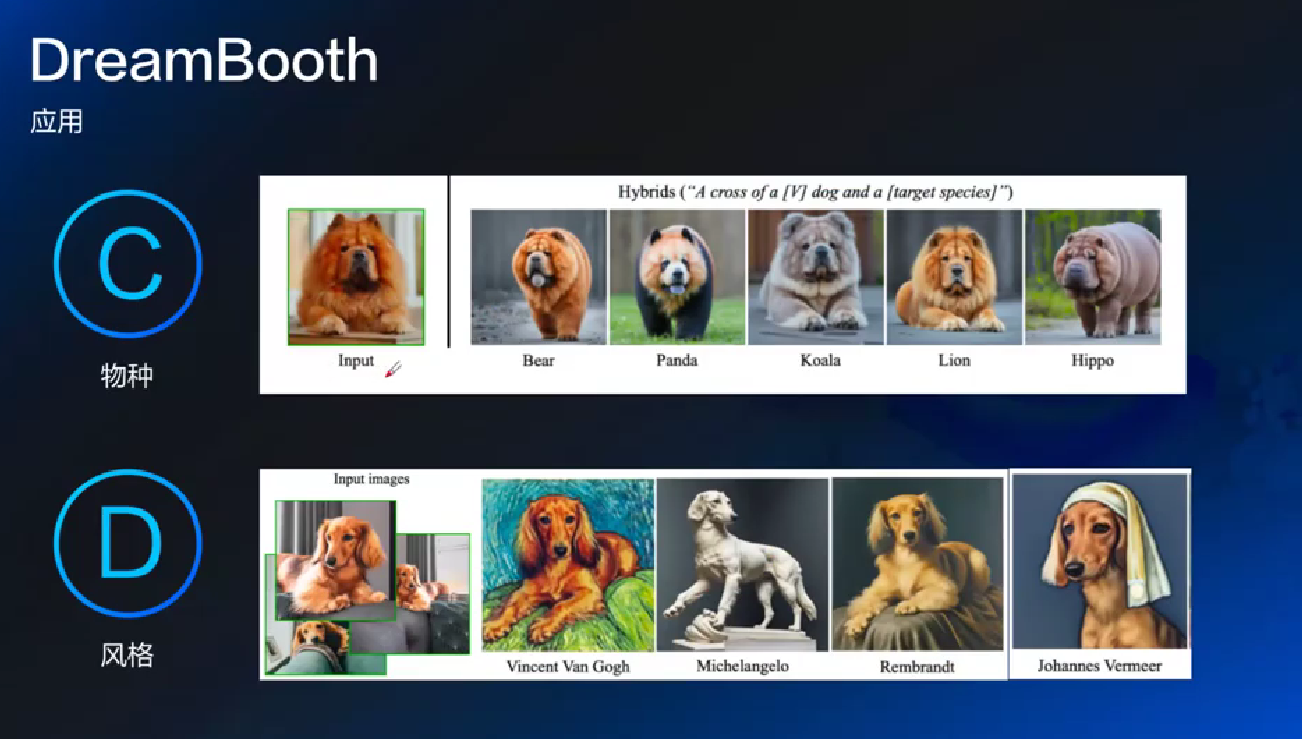


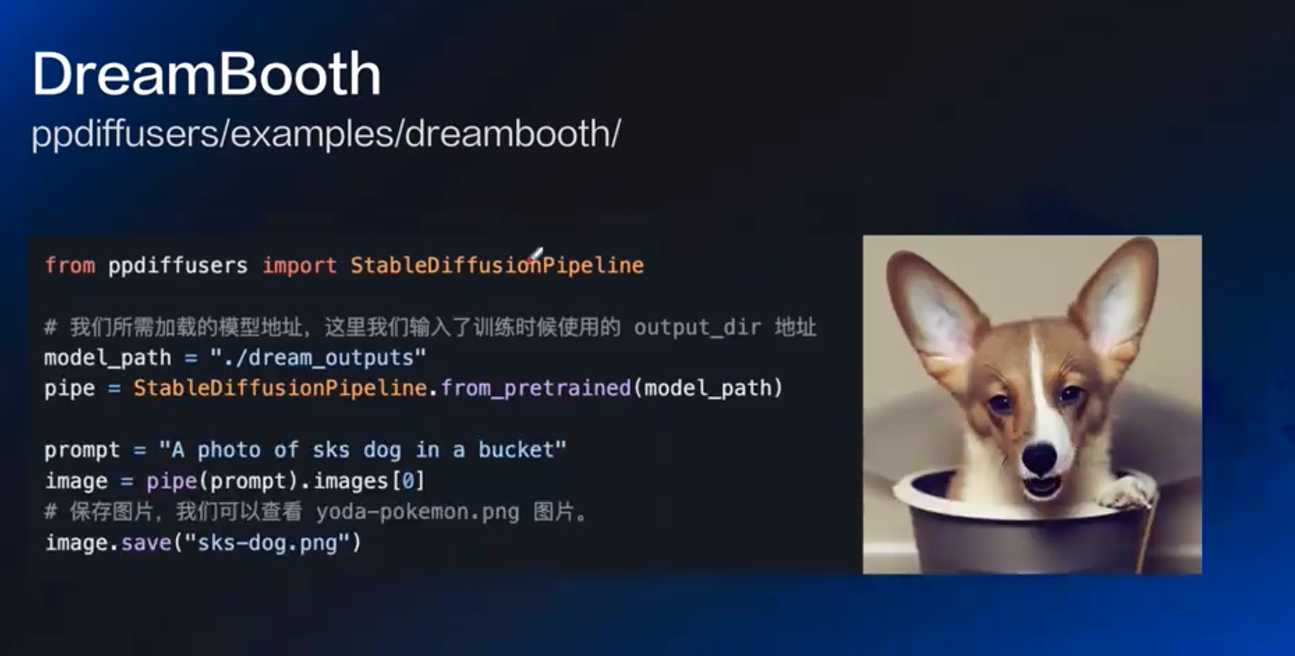
- instance_prompt: 你给的这些图是什么

civitai
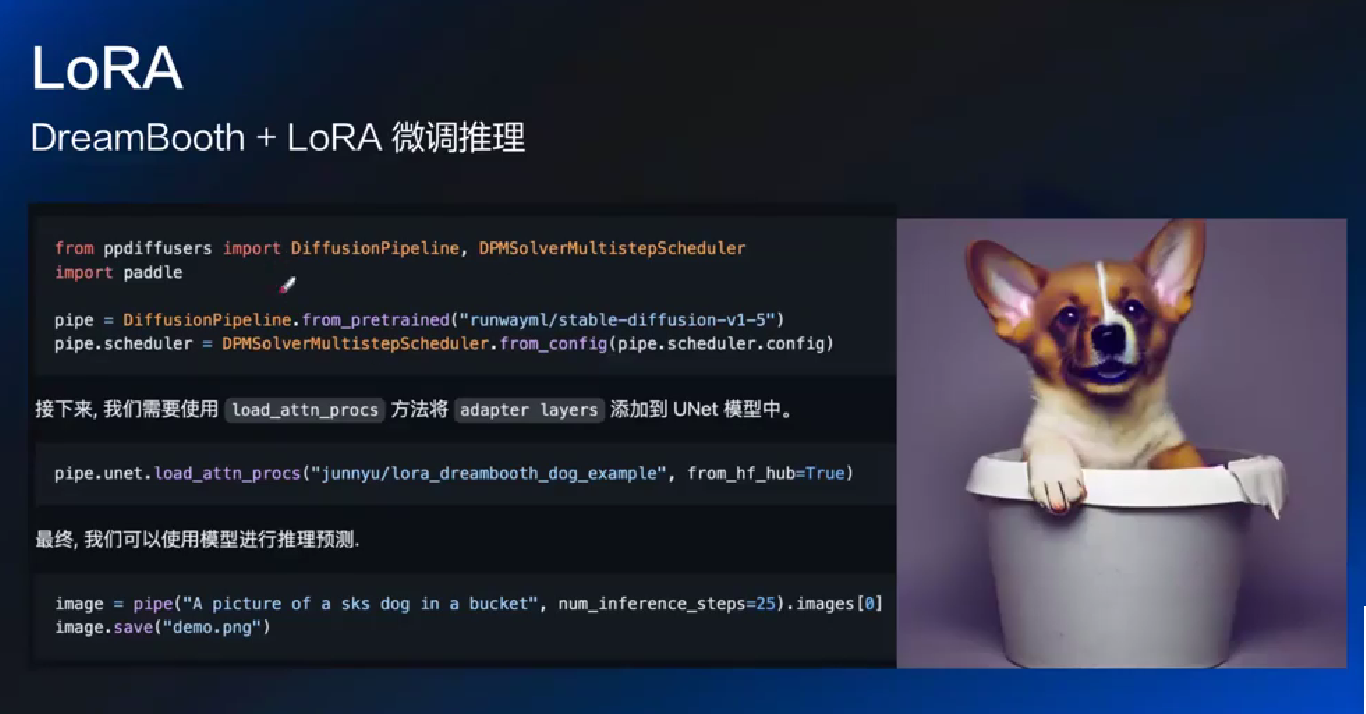
DreamBooth 对所有参数更新, 开销巨大, 而 lora 只更新部分

灾难性遗忘, 比如 DB 因为整个改变, 所以可能会忘掉一些什么
scale: 比如 0.7毕加索 0.5梵高

不会有「应该放在哪个地方」问题



- validation_prompt: 测试时的出图 prompt
- validation_epochs: 测多少步vali 一下

中途冻结 SD, copy, 再用 ControlNet 训练完融合回去
想详细了解去看论文



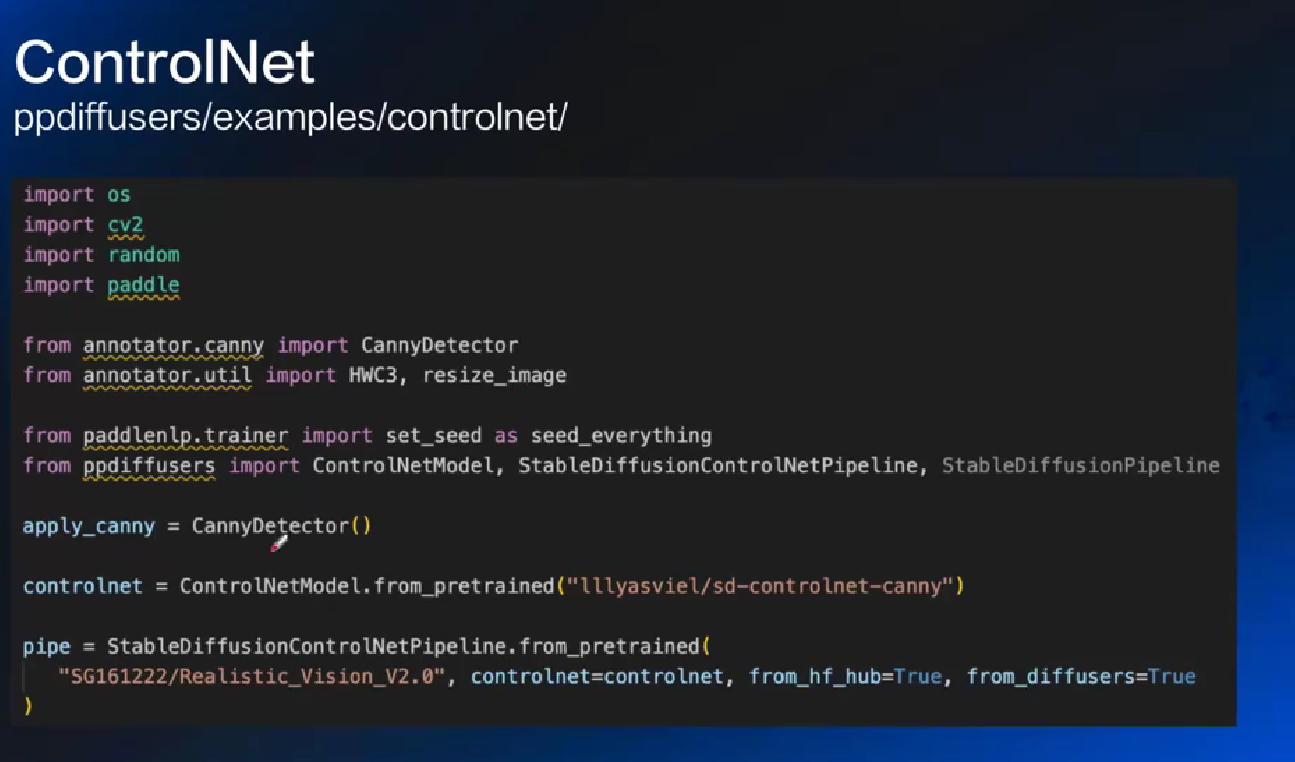





# 智能文档查询助手


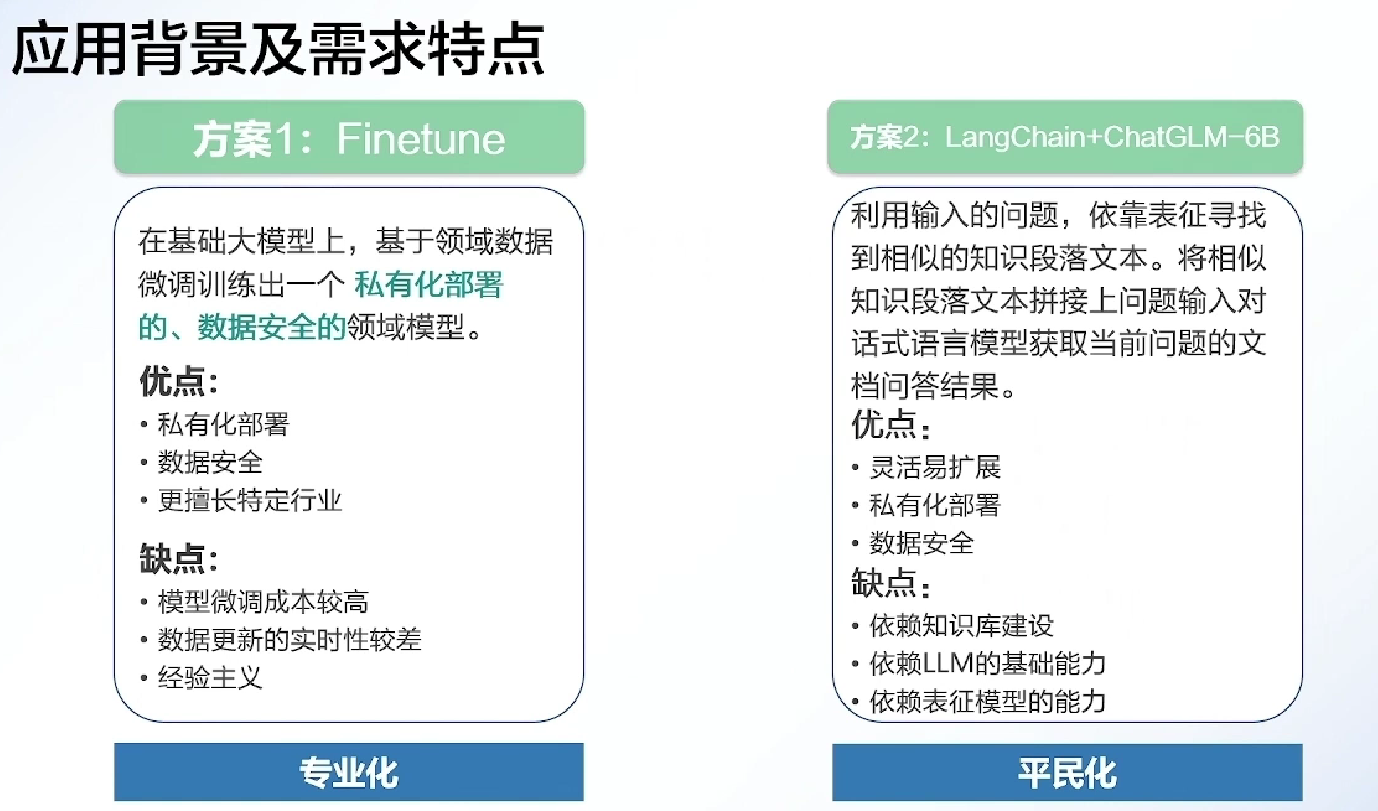
finetune因为需要频繁更新, 更适合专门的专业的人来干
能联合个人知识库??

- ptv: 帮助将输入转换为语言模型能理解的
- ir: 语言模型和文档更好地交互
- cmh: 历史管理




